品牌型号:联想ThinkBook
系统:windows10 64位旗舰版
软件版本:IBM SPSS Statistics 29.0
在数据分析领域,如果需要分析二分类因变量与多个自变量的关系,推荐使用SPSS二元Logistic回归的方法进行操作。为了使数据呈现更简洁易读,二元分类变量通常取值为0和1来代表不同的分类定义。今天,我们以SPSS二元Logistic回归是什么,SPSS二元Logistic回归怎么建模这两个问题为例,带大家了解一下SPSS二元回归的相关知识。
一、SPSS二元Logistic回归是什么
在研究多因素对某一变量的影响时,我们可以采用多重线性回归,但如果因变量为分类变量,例如阳性和阴性,而且因变量和自变量并不是线性关系,那么应当使用回归分析来研究,我们就在这里展示一下SPSS二元Logistic回归的操作过程。
1、下图为某医院探究成年男性吸烟、饮酒与冠心病关系的研究数据,分别是285例冠心病病例和705例健康人对照,0表示对照、不吸烟、不喝酒,1表示病例、吸烟、饮酒,接下来展示一下怎么对案例数据进行SPSS二元回归分析。
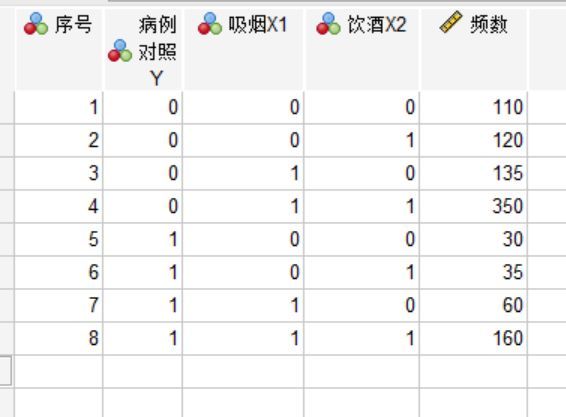
2、首先找到SPSS编辑栏【数据】模块的【个案加权】选项,我们需要对之后回归分析的依据进行确认,点击【个案加权依据】,将频数移动到【频率变量】栏,点击【确定】按键。
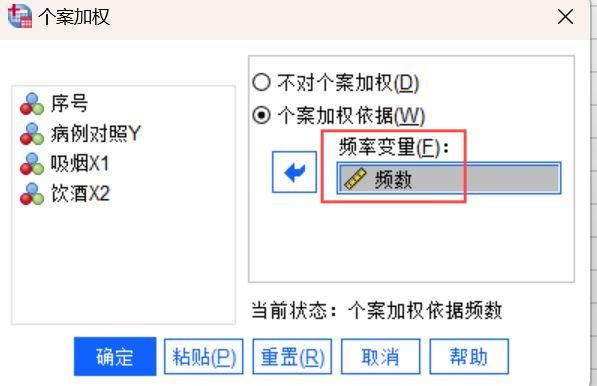
3、在编辑页面【分析】模块找到【回归】的【二元Logistic】选项,由此进入对案例数据进行二元回归分析的题项设置。
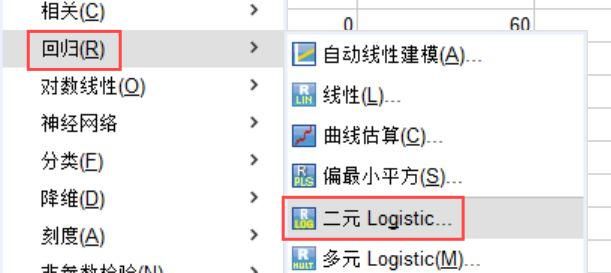
4、将病例对照Y移动到【因变量】,吸烟X1和饮酒X2移动到【块】,在下方的【方法】模块选择输入,这样就完成了对变量的设置操作,由此可以分析吸烟和饮酒情况对病例的非线性影响。
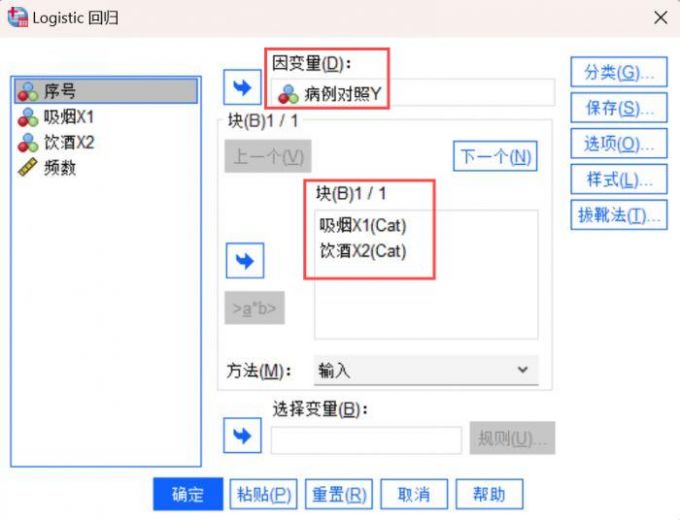
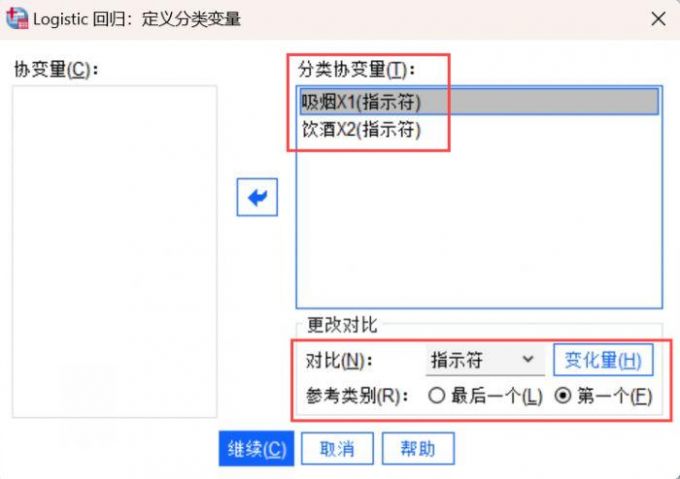
5、然后点击页面的【分类】模块,将吸烟X1和饮酒X2移动到【分类协变量】栏,在【更改对比】栏勾选【参考类别】的【第一个】,再点击【继续】按键。
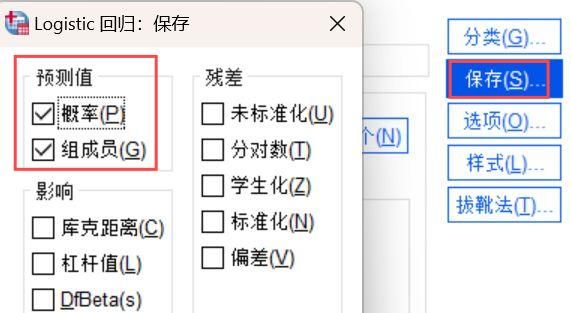
6、再点击【保存】模块,勾选【预测值】的【概率】和【组成员】,这样就能够后续查看回归分析的数据概率统计等相关信息。
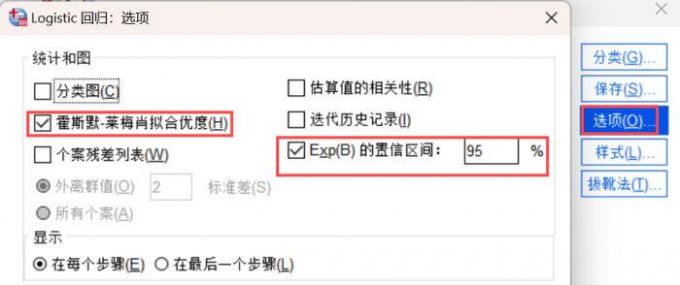
7、最后找到【选项】的【统计和图】模块,勾选【霍斯默莱梅肖拟合优度】,并且在置信区间填写95%,完成回归拟合优度和置信区间的设置。
二、SPSS二元Logistic回归怎么建模
根据上述操作,我们可以评估数据模型的拟合程度进而了解相关回归模型情况,接下来展示一下如何解读SPSS二元Logistic回归的模型信息。
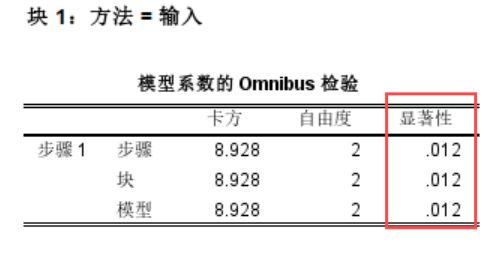
1、首先我们来看SPSS结果输出页面的模型系数检验,它是将纳入模型的所有自变量作为一个整体,通过下图数据,我们看到显著性p<0.05,表示至少有一个自变量可以解释因变量分类结果。
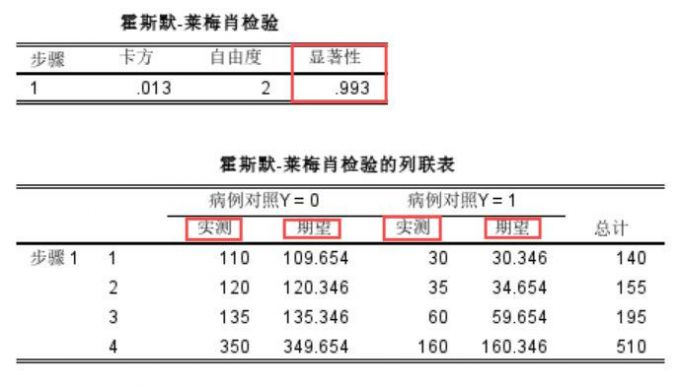
2、然后我们再看霍斯默相关检验情况,这用于评估二元回归模型的拟合优度,下图显著性p值为0.993大于0.05,表明观测值和预测值适配。在列联表,我们可以清晰看到病例和健康人对照数据在实测和期望方面的数值,总体上案例数据模型拟合好。
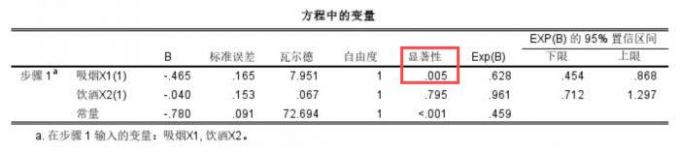
3、最后在方程变量结果图,B表示回归模型系数,瓦尔德用于检验回归系数是否显著,从表中可以看到,吸烟回归系数为0.465,wald值为7.951,显著性p<0.05,证明吸烟与患冠心病之间存在关联,而饮酒p值大于0.05,无足够证据表示饮酒和患冠心病之间存在关联。
三、小结
以上就是SPSS二元Logistic回归是什么,SPSS二元Logistic回归怎么建模的解答。如果我们想要检测庞杂数据集的模型拟合度,推荐使用SPSS二元回归分析的方法进行观测,便于后续对观测值的准确判断。最后,也欢迎大家前往SPSS的中文网站,学习更多关于数据分析的操作技巧。
