品牌型号:联想ThinkBook
系统:windows10 64位旗舰版
软件版本:IBM SPSS Statistics 29.0
在进行数据多因素回归分析之前,推荐运用SPSS共线性诊断来检验自变量之间是否存在线性相关性,由此可以筛选、剔除高度相关数据来保证后续回归模型的优化改进。今天,我们以SPSS共线性诊断指标怎么看,SPSS共线性诊断VIF值过高怎么处理这两个问题为例,带大家了解一下SPSS共线性诊断的相关知识。
一、SPSS共线性诊断指标怎么看
当分析多个自变量对某一变量的影响,我们还需要注意自变量之间的关系,例如各个变量之间是否有高度相关的线性关系,以免后续数据建模的模型不稳定等问题出现,这里我们展示一下SPSS共线性诊断指标怎么看的过程。
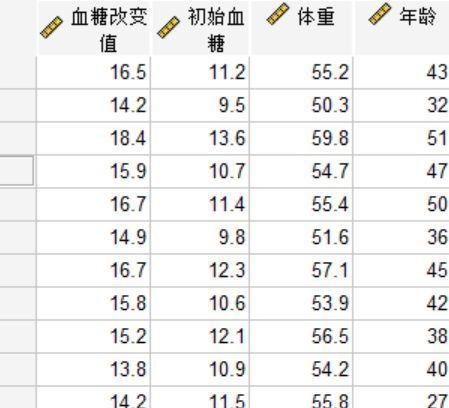
1、如下是某医院对多名糖尿病患者的检测数据,血糖改变值作为因变量,我们需要检测初始血糖、体重和年龄这些变量之间是否存在相关线性关系。
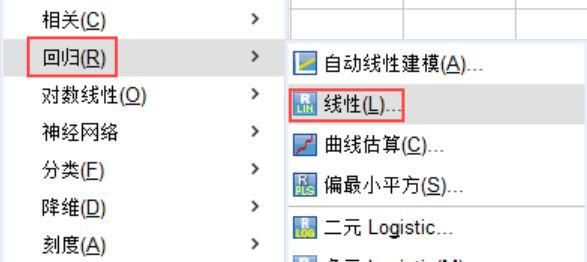
2、在SPSS编辑页面找到【分析】栏的【回归】模块选择【线性】,进入其间共线性诊断的操作页面和题项设置。
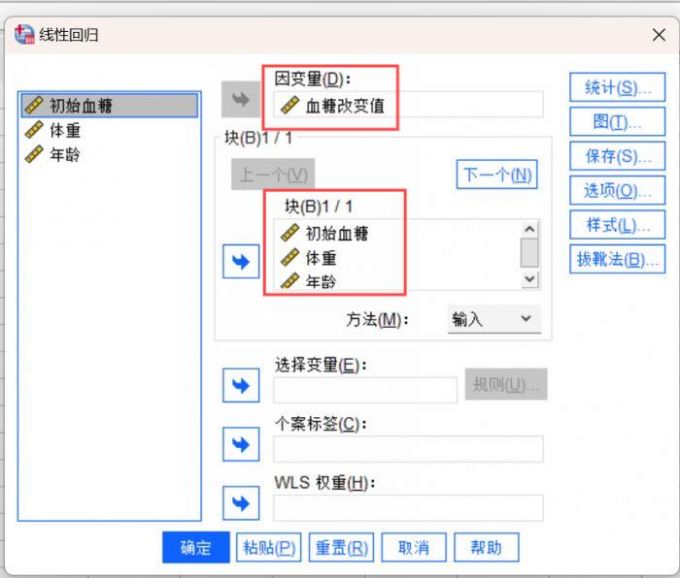
3、接下来将血糖改变值移动到【因变量】,将初始血糖、体重和年龄移动到【块】,在下方的【方法】模块选择【输入】,完成共线性的变量设置。
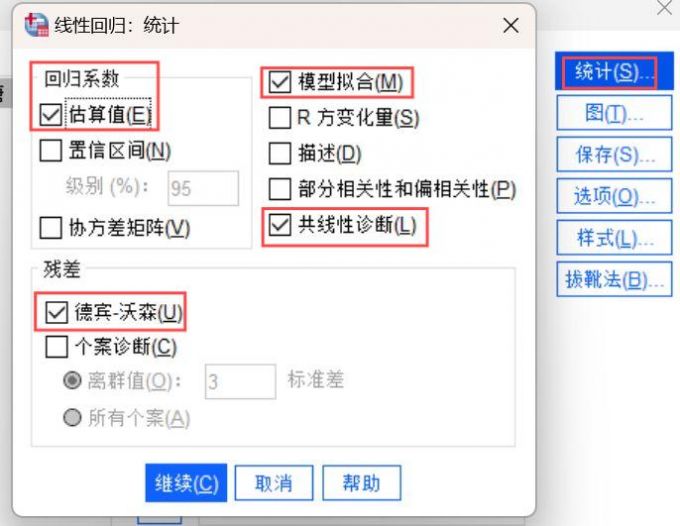
4、找到线性回归页面【统计】栏的【回归系数】模块,勾选其中的【估算值】,再勾选【模型拟合度】和【共线性诊断】以及【残差】模块的【德宾沃森】,然后点击【继续】按键。
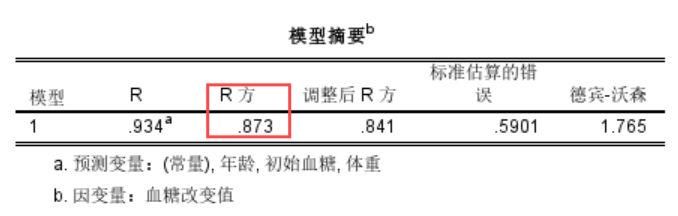
5、然后我们可以在SPSS输出页面得到模型摘要的数据,R方代表模型拟合度,取值在0到1之间,越接近1表示模型拟合度越好,这里的R方值为0.873表示案例数据的模型拟合度好,可以看后续的数据结果。
二、SPSS共线性诊断VIF值过高怎么处理
如果发现SPSS共线性诊断VIF值过高,我们能够得出有变量存在高度相关性的情况,这样容易导致回归系数偏离真实值甚至数据模型扭曲的结果,所以我们需要对高相关度变量进行筛选和移除,对采集数据进行标准化,或者将高度相关变量合并为一个新的变量。
1、按照上述步骤,我们得到ANOVA分析图表,可以看到回归的显著性p<0.05表示模型构建有意义,由此可以查看后续的分析测验结果。

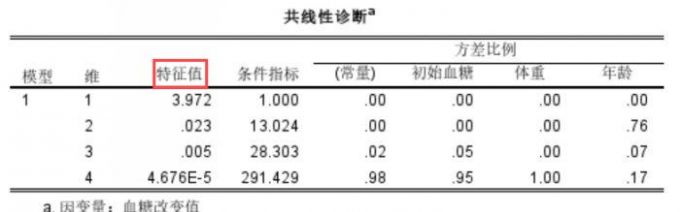
2、在共线性诊断图表,我们能看到数据模型在不同维度的特征值和条件指标,1维特征值为3.972,2维特征值为0.023,3维特征值为0.005。
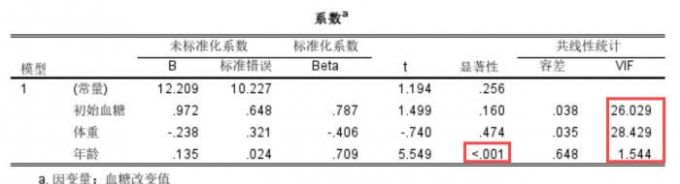
3、最后我们在系数列表看到显著性和VIF值测量结果,年龄显著性p<0.05表示年龄对血糖改变值存在显著影响,而初始血糖和体重VIF值分别为26.029和28.429,当VIF>10表示变量之间严重多重共线性,需要斟酌删除相关变量。
三、小结
以上就是SPSS共线性诊断指标怎么看,SPSS共线性诊断VIF值过高怎么处理的解答。如果想要判断自变量之间是否存在线性关系及关系强度,推荐运用SPSS共线性诊断进行分析,由此筛选和保留合适的变量进行后续的数据模型搭建。最后,也欢迎大家前往SPSS的中文网站,学习更多关于数据分析的操作技巧。
